

Introduction
Objet du document
Dans un monde où la gestion rapide et efficace de l’information est cruciale, BLUEWAY se distingue par sa capacité à exploiter intelligemment la mémoire, offrant ainsi des performances exceptionnelles dans le traitement et la manipulation des données.
L’objectif de ce document est de décrire précisément toutes les étapes à accomplir pour optimiser les flux en utilisant la mémoire :
- Blueway instructions
- Services optimisés
Blueway instructions
- D’abord on décrit les instructions utilisées dans l’optimisation des flux en mémoire.
- Load_View_InMemory : Cette instruction vous permet de charger des données inMemory depuis plusieurs tables d’une même base. Vous pouvez ainsi exécuter une requête SQL multi-tables. Autre avantage de l’instruction Load_View_inMemory : de forts gains de performances ! En effet, cette instruction ne charge que les données requêtées, et non pas toute la table. Le principe est de charger en mémoire le résultat de votre requête au travers d’un service et d’un support inMemory custom, afin de réaliser les traitements associés. Cette instruction peut être suivie par un « Sql inMemory » pour réaliser des traitements de masse, mais peut être aussi l’objet d’un « Read » classique pour réaliser des traitements unitaires.
Comment utiliser cette instruction ?
- Glissez-Déposez le support à lire dans le champSupport
- Saisissez votre requête SQL dans le champ Instruction SQL sans oublier les doubles quotes autour de la requête.
- Saisissez le nom du support InMemory à créer dans le champ En retour
- Sauvegardez et livrez
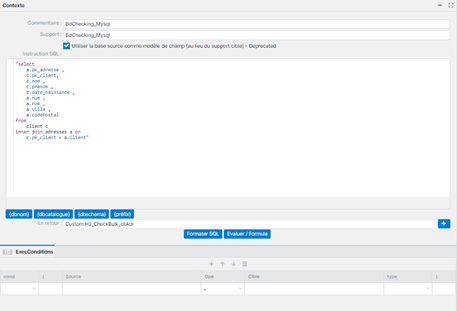
Format SQL : Permet de formater automatiquement votre requête et gagner en lisibilité
En retour : Le nom du support doit être au format Custom.nomdusupport. Après avoir cliqué sur le bouton +, Phoenix crée automatiquement un support de travail InMemory dans la catégorie Custom. Ce support prend automatiquement les colonnes et la structure correspondant à votre requête. Les champs sont alors créés par défaut avec un type varchar de longueur 255.
Avertissement : Selon le traitement à venir, il est nécessaire d’adapter la table H2 en modifiant le type de champ, sa longueur, et ses indexes. Attention, il faut alors reglisser le support dans le service pour la prise en compte de ces éléments.
- Load_InMemory : Cette instruction permet de charger un support inMemory à partir de données issues d’un support physique défini dans Phoenix et éligible au inMemory (Vérifier les limitations ‘H2’ du support).
Avertissement : C’est un prérequis obligatoire à toute manipulation mémoire.
Le résultat de la requête est chargé dans le support InMemory associé au support physique traité, disponible sous le menu Support interne/H2 inMemory.
Comment utiliser cette instruction ?
Insérer l’instruction dans un service, et faites-y glisser :
- Le support physique source (obligatoire)
- Les DataConditions (optionnel)
- La clé primaire « unique » : Obligatoire en cas d’opérations d’update
- Les indexes à créer en mémoire (optionnel) pour les futurs traitements de manipulation. Cette information peut vous faire gagner un gain de temps considérable.
Il est possible de spécifier la ou les colonnes qui seront considérées comme index en spécifiant un nom d’index dans le champ Nom index.
La colonne « ignore » permet d’écarter le chargement de certaines données : par exemple trop lourde, ou de typage incompatible.
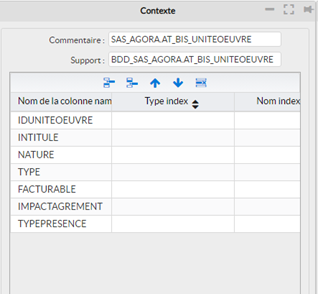
Par exemple ici le support physique (table dans une de données) c’est la table AT_BIS_UNITEOEUVRE (Table cible qu’on va alimenter).
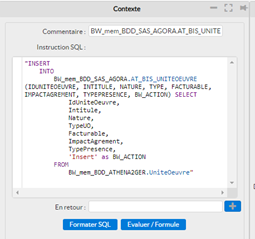
- Sql_InMemory : Cette instruction permet de lancer une requête sur un ou plusieurs supports InMemory, et d’alimenter un support InMemory cible ou même un support de travail.
La requête sql doit être conforme à la norme H2. Pour plus d’information : http://www.h2database.com/html/grammar.html .
Comment utiliser cette instruction ?
- Glisser Sql_InMemory dans l’algorithme de votre service
- Depuis le panneau Contexte, saisissez votre Instruction dans le champ Instruction SQL
Vous avez également la possibilité :
- D’ajouter un commentaire sur cette instruction qui sera ensuite visible dans l’algorithme de votre service
- De formater automatiquement votre requête et gagner en lisibilité en cliquant surFormater SQL
- D’évaluer votre instruction en cliquant sur Evaluer/ Formule
- Créer le support de travail si nécessaire sur le champ ‘En retour‘. Après avoir cliqué sur le bouton +, Phoenix crée automatiquement un support de travail.
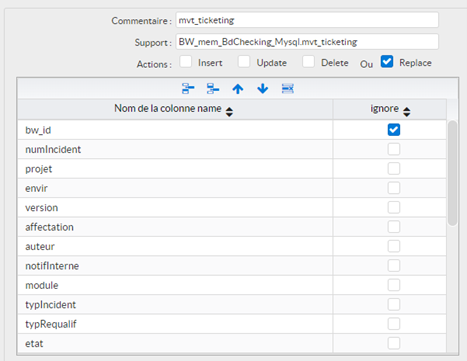
- InMemory_to_Physical : Cette instruction permet de mettre à jour un support physique à partir des données de son support InMemory, sur un ou plusieurs types d’action : ajout, mise-à-jour, suppression OU remplacement. Dans ce dernier cas, le support physique cible est vidé et remplacé par le inMemory.
Cette instruction n’est supportée que par des supports InMemory.
Une fois cette instruction exécutée :
- Le support inMemory est supprimé, même si toutes les lignes n’ont pas été traitées.
- Les variables éditeurs indiquent le nombre d’enregistrement traité (impactedLineUpdate, impactedLineInsert, impactedLineDelete).
Prérequis de traitement :
- Pour un support cible de type fichier plat, il faut avoir renseigné le _var_support du support physique.
- Il faut avoir créé et chargé un support InMemory via une instruction Load InMemory ou Load View InMemory.
- Pour les actions de type mise à jour et suppression, il faut également avoir indiqué un identifiant unique lors de la création du inMemory.
Comment utiliser cette instruction ?
Pour utiliser cette instruction :
- Glisser l’instruction dans l’algorithme de votre service
- Glisser le support InMemory
- Sélectionner la ou les actions (Insert, Update, Delete, Replace). Les actions Insert, Update et Delete peuvent être mixées, au contraire de l’action Replace.
- Insert coché : les lignes pour lesquelles BW_ACTION = Insert sont traitées
- Update coché : les lignes pour lesquelles BW_ACTION = Update sont traitées
- Delete coché : les lignes pour lesquelles BW_ACTION = Delete sont traitées
- Replace coché : ATTENTION à l’utilisation de cette option : le support physique cible est vidé et alimenté avec les données du support inMemory
- Cocher les champs à ignorer (applicable uniquement dans les cas Insert et Update, pour les supports physique base de données) : ces champs seront ignorés lors du déversement dans le support physique.
- En mode Insert, les champs prennent leur valeur par défaut (définie dans la base de données, attention aux champs NON NULL).
- En mode Update, les champs conservent leur valeur existante.
Services optimisés
Nous allons parler de chaque service évoqué qui ont été mis à jour :
- On commence par AGORA_S001_Load_BIS, dans ce service on a créé des groupes qui rassemblent les instructions dédiées à l’alimentation de chaque table associée à chaque groupe comme par exemple le groupe UNITEOEUVRE avant l’optimisation comme on voit dans la figure ci-dessous

Les instructions utilisées ici sont les instructions ordinaires pour alimenter la table AT_BIS_UNITOEUVRE en lisant la table UniteOeuvre ligne par ligne et les insérer dans la table AT_BIS_ UNITOEUVRE ligne par ligne ce qui va prendre beaucoup du temps, alors nous avons l’idée d’optimiser en exploitant les privilèges de Blueway en utilisant la capacité mémoire comme on voit dans la figure ci-dessous
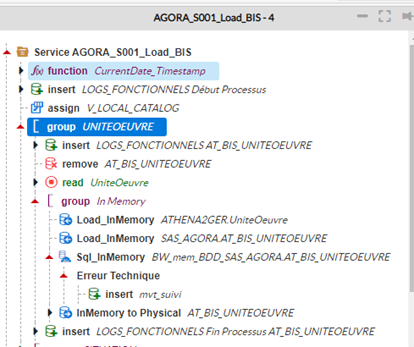
Les instructions InMemory utilisées ont le but de charger la table source dans un support mémoire (table dans la mémoire) en lui donnant une requête avec les conditions qu’on veut, et ensuite alimenter la table cible dans l’instruction InMemory_to_Physical d’une durée beaucoup plus moins que la manière traditionnelle celle non optimisée.
Dans ce service, dans tous les groupes on a adopté cette façon pour alimenter les tables sauf le groupe INDIVIDU on a pas adopté cette optimisation pour des raisons que ça ne prend pas du temps (la quantité de données n’est pas énorme).
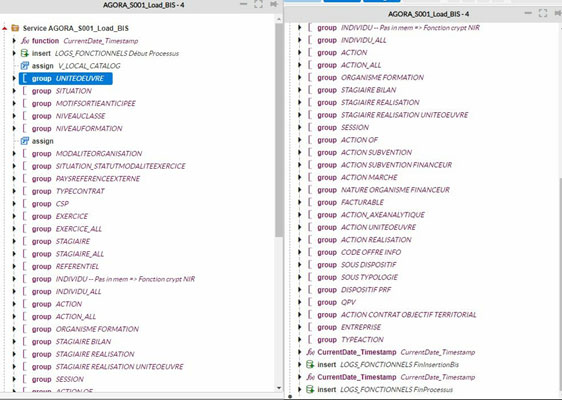
- Dans la figure ci-dessus on voit les groupes dans le service optimisé AGORA_S001_Load_BIS-4 et que le groupe INDIVIDU écrit sur son nom « pas in mem ».
En plus, dans ce service on a créé la table D_EXCEPTIONS pour éviter d’écrire une énorme requête avec une condition sur les 472 exceptions, comme on voit dans la figure ci-dessous
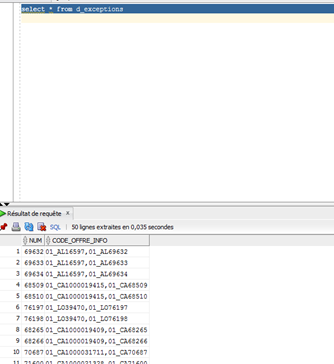
- Dans le groupe ACTION qui alimente la table AT_BIS_ACTION, on a modifié la requête dans l’instruction Load_View_InMemory pour charger dans la view les données datant de moins 5 ans.
- On va parler deuxièmement du service AGORA_Load_S001_Delta qui est optimisé en utilisant la mémoire dans l’alimentation des nouvelles informations en plus dans les tables alimentées par le service AGORA_S001_Load_BIS, dans la figure ci-dessous on voit la différence entre avant et l’optimisation après
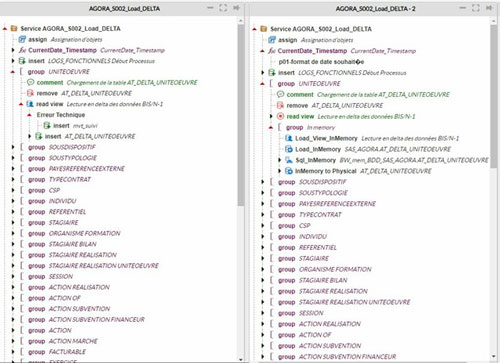
Attention : le groupe Action qui alimente la table AT_DELTA_ACTION n’est pas optimisé parce qu’il y avait des problèmes techniques dans Blueway.
- Troisièmement, on a le service AGORA_S005_Load_SasAgora où nous avons fait les mêmes optimisations en passant par la mémoire comme les services avant, par contre ici il y en a plusieurs groupes qui ne sont pas optimisés à cause des problèmes technique dans Blueway comme 1-PERSO STAGIAIRE 5-Enrichissement MDM GEO 8-DOSSIER DE FORMATOIN HP=>P dans ces groupes là on a utilisé l’instruction read_view, celle-là est de type boucle elle doit passer chaque ligne par ligne pour alimenter la table par l’instruction Insert chaque ligne par ligne également ce qui est lent.
Voici ci-dessous une photo du service et les groupes dedans
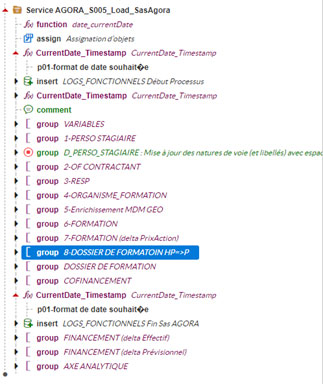
- Quatrièmement, on a le service AGORA_S004_Load_N1 où nous avons adopté la même façon d’optimisation en adoptant les instructions de mémoire comme par exemple dans le groupe UNITOEUVRE dans la figure ci-dessous
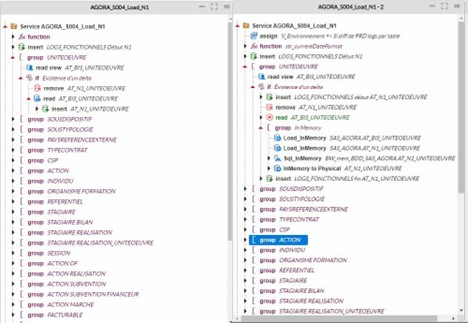
La version initiale est celle à gauche comme on voit la façon traditionnelle on utilise l’instruction read qui lit la table ligne par ligne et les insère à l’aide de l’instruction insert dans Blueway, par contre dans la partie à droite on a la version optimisée où les instruction Load_InMemory, Load_ViewInMemory, Sql_InMemory, InMemory_toPhysical pour optimiser le flux, dans cette version 2 tous les groupes sont optimisés.
